class: center, middle, inverse, title-slide # Do You Feel Like Who You Follow? ## A Network Approach to Predicting Individual Differences in Mental Health on Twitter. ### Cory K Costello & Sanjay Srivastava ### 2019-06-05 --- # Mental Health & Twitter ??? + At the broadest level, we're interested in predicting psychological characteristics from records of Online behavior. -- ## Why Mental Health? ??? + We're focusing on mental health now because **predicting mental health from online records has several potential benefits** -- + Potential Benefits + Applications in Clinical Science + Applications in Public Health -- + Potential Risks: + threats to privacy + discrimination -- ## Why Twitter? + Most accounts are public. + Easy access to data. --- class: center, inverse, middle # Why followed accounts? ??? Many records available on twitter, like tweets, but we think there are some **unique advantages to followed accounts.** ---  ??? + These are a few of the accounts I follow and just from this you might be able to tell + my interest in psych / research + my interest in american politics (maybe even my partisan lean) + my need for political satire to cope with our current politics. + A lot about me is contained in my followed accounts --- # Why Followed Accounts? ??? Start with **The reason so much is contained in followed accounts is...** -- + Following accounts is how people control whom and what they see on Twitter. + Under users' direct control. + primary means for controlling the *content of their feed* -- + Minimal threshold of Twitter use + Better capture passive users -- + Potentially less overt impression management + Tweets can be signals, identity cues. + Followed accounts are behavioral residue. --- class: center, inverse, middle # Is mental health reflected in followed accounts on Twitter? ??? + What about mental health. Is our mental health reflected in the accts we follow? + We think there are several reasons it is. --- # Followed Accounts & Mental Health -- + Mental Health -> Followed Accounts + Information/Support Seeking + Homophily + Emotion Regulation Strategies ---  --- # Followed Accounts & Mental Health + Mental Health -> Followed Accounts + Information/Support Seeking + Homophily + Emotion Regulation Strategies -- + Followed Accounts -> Mental Health + Emotions evoked from Twitter Content -- + Followed Accounts <-> Mental Health Transactions --- # Overview of Study + **Overarching goal:** Develop and evaluate Followed-account-based assesment for mental health constructs. -- ## Initial Method Development + We predicted individual differences in **tweet sentiment** from **followed accounts** on Twitter -- ## Further Validation + Predicting individual differences in **Depression, Anxiety, Anger, and PTSD symptoms** from **followed accounts**. + *Under review as part of RR* ??? remember to say **further validation using psychometrically sound measures of mental health** --- # Sentiment + **Sentiment analysis** refers to scoring texts for the .green[*positivity*] or .red[*negativity*] of their content. -- + For example: + .green[Some texts are *wondefully positive!*] + .red[Others are *dreadfully negative*] + others are neutral ??? + wonderful & positive are positive words = pos. sentiment score. + dreadful and negative are negative words = neg. sentiment score. + third example has no positive or negative words. -- ## Why sentiment? + **Domain-relevance** + It is related to affect, well-being, and mental health. + .small[Park et al., 2012; Reece et al., 2017] + It is easy to score reliably from tweets. --- # Predictive Modeling Approach -- + Create a predictive algorithm and evaluate how it performs in new data -- + Data-driven -- + Attempt to avoid bias & capitalizng on chance ??? by taking steps like 10-fold CV in training and evaluating model using holdout sample. -- ## Challenges: + More predictors than observations + Sparsity + Most followed accounts have few followers. --- # Sparsity  --- # Predictive Modeling Approach + Create a predictive algorithm and evaluate how it performs in new data + Data-driven + Attempt to avoid bias & capitalizng on chance ## Challenges: + More predictors than observations + Sparsity + Most followed accounts have few followers. ## Solutions: + Filter accounts (remove rarely followed accounts), data reduction, and modeling techniques. --- # Samples -- + We collected several samples of Twitter users through Twitter's API: -- + **Initial Sample:** randomly sampled from 3 networks .small[+ my 2-step friend network + Obama's followers + Trump's followers] -- + **Replication Sample:** randomly sampled followers of 10 accounts: .small[.pull-left[ + @joelembiid + @katyperry + @jimmyfallon + @billgates + @oprah ] .pull-right[ + @kevinheart4real + @wizkhalifa + @adele + @nba + @nfl ]] -- .pull-left[ + We only included users that: + had their language (on Twitter) set to English + `\(\geq\)` 25 tweets + `\(\geq\)` 25 friends ] -- .pull-right[ + <table> <thead> <tr> <th style="text-align:left;"> sample </th> <th style="text-align:left;"> \(N_{users}\) </th> <th style="text-align:left;"> \(N_{followed}\) </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Initial </td> <td style="text-align:left;"> 484 </td> <td style="text-align:left;"> 237, 930 </td> </tr> <tr> <td style="text-align:left;"> replication </td> <td style="text-align:left;"> 129 </td> <td style="text-align:left;"> 54, 262 </td> </tr> </tbody> </table> ] --- # Procedure + For both samples, we collected **followed accounts** and **tweets** -- + Then we scored all of the participants tweets for **sentiment** using the NRC sentiment lexicons (Mohammad & Kiritchenko, 2015) -- + We then went through our modeling procedure treating average tweet sentiment as the outcome variable. --- # General Modeling Approach: 1. Partition Data (60-40 split) 2. Process & Reduce Predictors: + filter accounts based on followers in data + Any further data reductoin. 3. Train & Evaluate Models using 10-fold CV 4. Select Model based on Training Performance and Interpretability 5. (Publically Register Training Results & Model Selection on OSF) 6. Evaluate out-of-sample accuracy with heldout data --- # Specific Models -- We chose four models based on: -- + Maximizing predictive accuracy & interpretability -- + What techniques work well with *numerous*, *sparse* & *noisy* predictors -- + What has been used in previous work. <table> <thead> <tr> <th style="text-align:left;"> models </th> <th style="text-align:left;"> reason </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Unsuperivised Ridge PCR </td> <td style="text-align:left;"> previous work* </td> </tr> <tr> <td style="text-align:left;"> Relaxed LASSO </td> <td style="text-align:left;"> previous work** </td> </tr> <tr> <td style="text-align:left;"> Supervised PCA </td> <td style="text-align:left;"> easy to interpret; good for low signal:noise </td> </tr> <tr> <td style="text-align:left;"> Random Forest </td> <td style="text-align:left;"> good for sparse predictors, low signal:noise </td> </tr> </tbody> </table> .small[+ *Kosinski et al., 2013 + **Youyou et al., 2015] --- class: center, middle, inverse # How accurately can we predict Tweet Sentiment from Followed Accounts? --- # Training Results: Initial Sample  ??? **Pause.** **describe axes** **random forest performed best and was selected** --- class: center, middle, inverse # Out-of-sample Accuracy: # *R* = .42 ??? + The correlation means that predicted scores correlate .42 with observed scores in the heldout data. + using just followed accounts **in new data** we can recover users' average sentiment with considerable accuracy. --- # Training Results: Replication 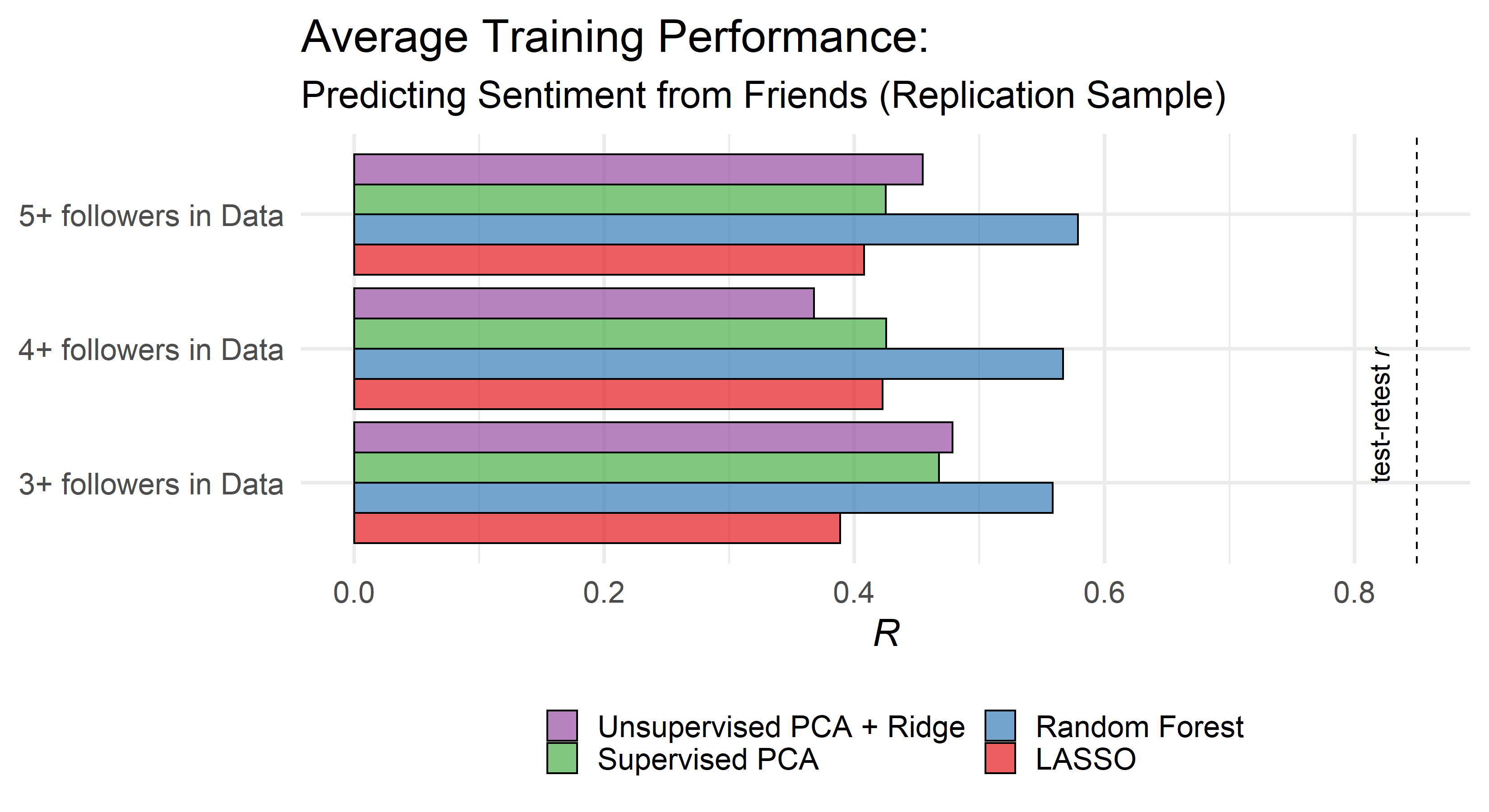 ??? + replication, very consistent which was **relieving** --- class: center, middle, inverse # Out-of-sample Accuracy: # R = .61 --- # Conclusions & Next Steps + Our initial results suggest followed accounts may be psychologically meaningful. -- + Followed accounts do predict sentiment with considerable accuracy. -- + Increased confidence that followed accounts relate to mental health. + However, very different DV and sampling plan. --- # Acknowledgements: ## Funding + NIH R21 MH106879-01 + NSF GRANT #1551817 ## Collaborators + Coauthors: Sanjay Srivastava, Reza Rejai, & Maureen Zalewski + PSD Labmates for feedback --- class: center, inverse, middle # Questions Email: ccostell@uoregon.edu Twitter: @costellock OSF Project Page: https://osf.io/ky7u3/